
Materiaalinformatica - het gebruik van gegevens en AI-methoden om het gebruik, de selectie, de ontwikkeling en de ontdekking van chemicaliën en materialen beter te begrijpen - is een van de meest zichtbare en opwindende manieren waarop digitale transformatie de chemische en materiaalindustrie beïnvloedt. De algemene hype rond AI is overgegaan in MI, met startups die de afgelopen drie jaar miljoenen hebben opgehaald en toonaangevende spelers die een revolutie beloven in de manier waarop de industrie werkt. Ondanks de hype blijft de werkelijke rol van deze technologieën enigszins duister, vooral voor de meer ontwrichtende benaderingen. De belangrijkste redenen hiervoor zijn het gebrek aan gegevensvolume, -formaat en -infrastructuur, en culturele weerstand. Dat gezegd hebbende, hebben veel internationale bedrijven hun MI-strategieën opgezet door samen te werken met een startup, hun eigen MI-afdeling te vormen of zich aan te sluiten bij een consortium. Deze recente activiteiten duiden op een sterk momentum, dat zich in versneld tempo zal voortzetten.
Er bestaat geen consensus over de "juiste" manier om MI-toepassingen te definiëren. Op basis van ons onderzoek en gesprekken met de belangrijkste belanghebbenden verdelen we de toepassingen van MI in twee hoofdtypen en we geloven dat deze categorisering de eenvoudigste manier is om de MI-ruimte weer te geven. De twee categorieën zijn optimalisatie van bestaande chemische en/of materiaalstructuren en de ontdekking van geheel nieuwe chemische stoffen en materialen, inclusief de synthetische route. Alle optimalisatiegevallen, ongeacht de specifieke context, kunnen worden gezien als multivariabele optimalisatieproblemen waarbij het doel is om de beste set parameters te vinden die overeenkomt met de kenmerken die moeten worden geoptimaliseerd, zoals het type chemicaliën/materialen, verwerking, structuur, eigenschappen of prestaties. Aan de andere kant omvatten ontdekkingsgevallen vaak het genereren van nieuwe chemische structuren met voorgestelde synthetische routes om ze te maken. Om het landschap van de belangrijkste spelers in deze twee toepassingen te begrijpen, hebben we een lijst gemaakt van de belangrijkste MI-spelers uit het bedrijfsleven, het midden- en kleinbedrijf (MKB) en onderzoeksinstellingen en deze spelers uitgesplitst naar geografie. Door middel van deze analyse hebben we de algemene trend van MI geïdentificeerd om bedrijven te helpen de juiste richting te vinden voor het opbouwen van een MI-strategie.
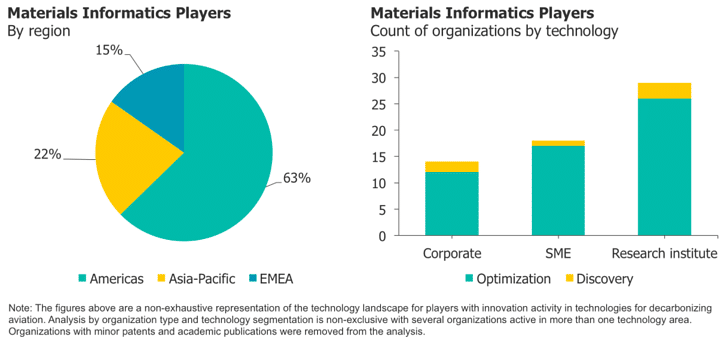
Uit onze gegevens blijkt dat Noord- en Zuid-Amerika het grootste aantal Mi Spelers hebben en dat de meesten van hen in de VS gevestigd zijn.
Toonaangevende bedrijven zijn Schrödinger, Citrine Informatics, Kebotix en Uncountable. Canada heeft het grootste aantal nieuwe MI startups, zoals Phaseshift Technologies en AI Materia. De meeste spelers in Azië-Pacific zijn wereldwijde Japanse chemie- en materiaalbedrijven. Zoals we in een recent inzicht hebben vermeld, staan Japanse bedrijven het meest open voor MI, en veel van hen hebben hun MI-strategieën publiekelijk aangekondigd. Het is zeker dat er veel meer chemische bedrijven zijn met actieve MI-inspanningen die niet openbaar zijn gemaakt, vooral in de VS en de EU.
De leidende rol van onderzoeksinstituten geeft aan dat Mi zich nog in een vroeg stadium bevindt.
AI ontwikkelt zich snel en veel belangrijke AI-algoritmen moeten nog worden toegepast op chemicaliën en materialen. De meeste onderzoeksinstituten richten zich op het gebruik van nieuw ontwikkelde algoritmen bij het oplossen van optimalisatiegerelateerde use cases. De belangrijkste spelers zijn Stanford University, Northwestern University, MIT, het National Institute of Standards and Technology (NIST), het National Institute for Materials Science (NIMS), de University of Cambridge en de University of Toronto. Bovendien geeft de vergelijking van bedrijven en MKB-bedrijven aan dat meer wereldwijde bedrijven in de nabije toekomst met MI zullen gaan werken, vooral in Noord- en Zuid-Amerika en EMEA.

De meeste Mi activiteiten zijn in optimalisatie met traditionele Data Science methoden.
Dit komt door de uitdagingen op het gebied van gegevens in de chemische en materiaalindustrie. De industrie heeft niet alleen een gebrek aan voldoende gegevensvolumes, maar heeft ook niet één formaat (of zelfs maar een paar formaten) voor gegevens. Bovendien bevinden gegevens zich vaak overal binnen een wereldwijd bedrijf en het centraliseren ervan is een grote inspanning. Door deze factoren en de kosten om extra gegevens te verkrijgen, heeft de chemische en materialensector het meest te maken met "kleine en schaarse gegevens". Als gevolg hiervan werken traditionele statistische methoden (in plaats van het veelgehypte deep learning) vaak beter voor MI. Vaak zijn de beste gegevens beschikbaar voor optimalisatieproblemen, waardoor de meeste groepen aan dergelijke problemen werken.
De meeste spelers behoren tot de optimalisatiecategorie en richten zich op twee specifieke toepassingen.
Optimalisatie van formuleringen op basis van polymeren heeft de grootste commerciële interesse en is in toenemende mate technisch haalbaar. Recente computationele methoden zijn gebruikt om experimenten in deze toepassing te vervangen, waardoor het proces van gegevensverzameling wordt versneld. De tweede toepassing is de ontwikkeling van meerfasige legeringen. Omdat we een veel langere geschiedenis hebben in de metallurgie dan in andere materialen, zijn er veel meer gegevens beschikbaar voor het opbouwen van fasediagrammen. Met AI-tools wordt het relatief praktisch om fasediagrammen en/of fasegedrag van een bepaalde meercomponentenlegering te voorspellen, waardoor doelgericht legeringontwerp mogelijk wordt.
Discovery vertegenwoordigt een nieuwe golf van Mi, maar er blijven grote barrières.
De meest volwassen benaderingen richten zich tegenwoordig op kleine moleculen en de ontwikkeling van geneesmiddelen. Een typisch voorbeeld maakt gebruik van autoencoders om virtuele moleculebibliotheken te genereren voor modeltraining om de gewenste eigenschappen te selecteren. Na verschillende screeningsrondes door algoritmen en menselijke experts is het mogelijk om een paar testbare chemische kandidaten te hebben voor doeleigenschappen. Nadat de beste kandidaat is geselecteerd, kunnen onderzoekers synthetische routes plannen voor productie. Hoewel deze methode werkt voor kleine moleculen, is het nog steeds een uitdaging om deze te gebruiken voor macromoleculen zoals polymeren, omdat er geen bevredigende manier is om polymeren te noteren op een grote schaal die geschikt is voor deep learning.
Veel academische onderzoeksgroepen hebben optimalisatietechnologieën die nog niet gecommercialiseerd zijn. Tot de toponderzoekers behoren Dr. Taylor Sparks, Dr. Milad Abolhasani, Dr. Elizabeth A. Holm en Dr. Klavs Jensen. In de komende vijf jaar zullen er meer start-ups ontstaan op basis van onderzoeksinstituten en zal de nadruk liggen op optimalisatie, vooral van polymeren. Wat ontdekking betreft, zullen veel meer onderzoeksgroepen beginnen te werken aan niet-polymere chemicaliën en materialen, waarschijnlijk met behulp van generatieve tegenstrijdige netwerken (GAN's). Een deel van het werk zal lijken op wat is bereikt in de farmaceutische ruimte voor kleine moleculen - met bedrijven als AstraZeneca die de inspanningen leiden. Tot slot is laboratoriumautomatisering naar voren gekomen als een hardwareoplossing voor MI - waardoor het concept van het "autonome lab" is ontstaan. Deze trend zal zich in de nabije toekomst voortzetten, maar zal het tempo van pure MI-toepassingen niet inhalen.