
Synthetic biology has already experienced the downside of overhyped capabilities, as investment cycles from 2017 to 2021 were spurred by broad claims that failed to deliver commercial returns. Now, with the rise of AI, synthetic biology risks repeating the same pattern. AI is becoming a common fixture across synbio platforms, yet its actual necessity for these technologies is often ambiguous. While AI promises accelerated design cycles and improved performance, many platforms lean on the term as shorthand for advanced analytics, lacking demonstrable functional differentiation.
As such, this brief aims to break down the four use-cases of AI in synthetic biology — novel molecule discovery, strain/enzyme engineering (with iterative optimization), bioprocess optimization, and lab automation — and evaluate the functional necessity of AI in each. Understanding where AI is technically necessary (see table below) is essential to separate signal from noise in an increasingly crowded market.
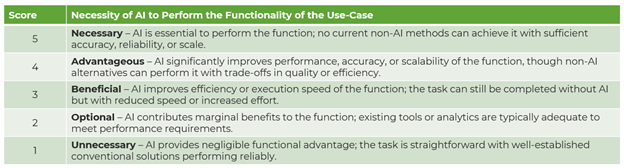
Where in Synthetic Biology is AI Most Helpful?
AI is Advantageous: Novel Molecule Discovery
The use of AI is largely critical in novel molecule discovery, not only in increased speed, throughput, and screening capacity but also in achieving unique properties and capabilities that can exceed what’s achievable by other processes. However, the use of AI is not the sole way to achieve novel compounds — randomized mutation and directed evolution can do so within certain parameters (e.g., what is possible via existing cellular metabolic networks).
“AI-driven novel molecule discovery” refers to the use of generative models namely to design proteins, polymers for materials, and pharmaceuticals, or any other compound not found in nature. Although based on a set of general biological and chemical properties, these models aim to navigate complex sequence-function relationships and explore uncharted design space beyond what homology-based or rule-based approaches allow.
While humans can analyze structure-function relationships, databases, and combinatorial chemistry to propose new candidates at low throughput, traditional analytics (e.g., QSAR models) can only correlate known structures, and they struggle to expand beyond known chemistry. Alternatively, generative models can develop nonintuitive, de novo molecules and explore orders-of-magnitude-larger chemical/sequence combinations than humans can.
This has been demonstrated by a study led by researchers at the University of Washington, who used a machine learning (ML) model to develop a novel luciferase enzyme with catalytic activity equivalent to the naturally occurring enzyme’s but drastically greater substrate specificity. The deep-learning platform used a familywide hallucination concept to generate over 1 million unique proteins with novel pocket shapes for binding specificity to improve functional performance. In addition to academic research, companies like Cambrium have leveraged generative AI and deep-learning platforms to develop novel molecules, including what the company claims is the first 100% human-skin identical collagen.
AI is Beneficial: Strain/enzyme Engineering (with Iterative Optimization)
Most AI applications in strain engineering adopt a top-down, predictive approach, starting with an existing strain or enzyme and applying rule-based models to evaluate the impact of discrete changes (e.g., gene knockouts). These models rely heavily on established biological and chemical principles rather than offering wholly generative, bottom-up solutions. The use of AI reflects high utility but not exclusivity, given that humans have long conducted strain optimization and that current models largely operate within human-defined frameworks.
“AI-driven strain/enzyme engineering” refers to the application of ML models to guide the generation of microbial strains or protein sequences for improved performance. Within the design-build-test-learn (DBTL) cycle, AI models predict fitness outcomes based on existing and preestablished sequences, select optimal variants to construct next, and identify nonobvious improvements through iterative feedback loops and analysis of experimental data, often using supervised learning, Bayesian optimization, or active learning frameworks.
While humans have conducted directed evolution, rational design, and pathway engineering through decades of accumulated domain knowledge and standard analytics, these approaches are limited by scale, slow feedback loops, and difficulty managing nonlinear mutational interactions or high-dimensional optimization problems. In contrast, AI enables exploration of large combinatorial sequence spaces, detects epistasis, and reduces the number of experimental cycles needed to reach high-performing solutions. Still, many of these improvements remain accessible without AI, especially in narrowly scoped or well-characterized systems.
This is exemplified by a study from Jiangnan University in which researchers applied a Bayesian optimization model, used to enhance fatty alcohol production in engineered microbes. Over multiple DBTL iterations, the AI model selected the most informative variants to test derived from well-characterized, preexisting strains; then, it narrowed down productivity to a specific genomic pattern, ultimately improving production titers by over 50% while reducing the number of required experiments compared with traditional design of experiments. Commercially, companies like Cradle Bio use generative protein models to develop novel enzymes or design de novo active sites, accelerating two-to-three-year development timelines to a few months and enabling more ambitious performance goals than manual strategies can reasonably support.
AI is Beneficial: Lab Automation and Robotics
AI enables dynamic decision-making, adaptive experiment planning, and self-guided iteration. Without AI, experimentation remains constrained by linear workflows and labor bottlenecks; however, many argue that human interpretation and creativity are core components of experimental design and require decision-making processes that can’t be replicated by AI. While AI is essential to realizing autonomous experimentation, it is not strictly required for basic lab automation.
“AI-driven lab automation” refers to the integration of ML with robotic experimentation platforms to autonomously design, execute, and analyze experiments in a closed-loop manner. Unlike conventional robotic systems, which follow prescripted workflows, AI-enabled platforms may actively learn from experimental results to iteratively choose the most informative or promising experiments to run next.
Traditional laboratory automation can greatly enhance throughput and reproducibility but remains static and dependent on human supervision to interpret data and plan next steps. However, importantly, AI-based adaptive experiment planning poses significant risk when targeting creative, out-of-the-box workflows to determine target conclusions for a given study.
One example is efforts at Lawrence Berkeley National Laboratory’s A-Lab, where researchers developed a closed-loop experimentation system that integrates ML with robotics to autonomously select, execute, and analyze experiments. The system achieved up to a 100-times improvement in throughput compared with human-driven workflows and is estimated to reduce a typical 10-year discovery timeline to under six months, highlighting the efficiency gains from AI-guided iteration but not unlocking any novel function compared with human-led experimentation. Similarly, Ginkgo Bioworks incorporates AI into its foundry automation platform to prioritize strain variants, pathway edits, and experimental conditions. By guiding robotic experimentation with predictive models trained on multiomic and historical data, Ginkgo accelerates design cycles across diverse applications. These examples illustrate how AI enhances speed and efficiency but is not essential for task completion.
AI is Optional: Bioprocess Optimization
For most industrial applications, bioprocess optimization can proceed effectively via sensors without AI, especially when operating conditions are stable or vary within known bounds, indicating that while AI adds some value in predicting nonoptimal conditions proactively or responding to variation while considering and responding to interdependencies, it does not fundamentally redefine the process space yet.
“AI-driven bioprocess optimization” refers to the use of ML models to predict, control, and improve process parameters in fermentation and downstream processing that affect cell health, mutation rates, and productivity. These models may be predictive (e.g., multivariate regression, neural networks) or adaptive (e.g., reinforcement learning), and are often deployed as digital twins to simulate and optimize process performance or integrated into real-time control systems.
Traditional methods, including sensor-based control loops and multivariate statistical analysis, can often provide sufficient insight and control for well-characterized systems. But they fall short in high-dimensional or nonlinear environments where unknown or interdependent factors affect process outcomes. AI augments these tools by detecting subtle correlations across large data sets, generalizing across operating ranges, and adapting control policies in real time.
A notable example is a study from University College London where researchers applied reinforcement learning to a simulated coculture bioreactor. In this case, an AI bioprocess development simulator learned to dynamically adjust nutrient feed and flow rates to maximize productivity while maintaining species balance — something traditional proportional-integral-derivative controllers failed to achieve. In industry, platforms like Pow.Bio provide AI-enhanced analytics that uncover hidden sources of bioprocess variability, enabling biomanufacturers to identify critical process parameters and minimize off-spec production; this is particularly useful in scaling early stage continuous fermentation platforms, where interdependent bioreactor condition variables can highlight potential mutation and contamination early on.
The Lux Take
As AI’s highest impact is in use-cases where it enables fundamentally new capabilities, not simply more efficient versions of existing workflows, clients should view much of AI’s current necessity in synthetic biology as overstated, but this could change pending technical developments in a few areas. First, the necessity of AI in strain and enzyme engineering could increase over time as synthetic systems become more modular and bottom-up cell construction becomes tractable. If these systems evolve from predictive to generative platforms, capable not just of recommending variants but also of proposing entirely new functional architectures, AI will shift from helpful to indispensable. Second, if AI in bioprocessing advances beyond pattern recognition into holistic, anticipatory control systems, capable of detecting and responding to challenges like contamination or metabolic drift before they manifest, it could become critical for complex, highly variable biomanufacturing processes. AI for bioprocess optimization is likely to become increasingly necessary over the next two to three years as companies like Pow.Bio are already working to integrate anticipatory control ML systems. In contrast, AI’s role in strain engineering remains stagnant, and meaningful progress will depend on breakthroughs in cell construction (e.g., synthetic system) technologies, research that may take five to 10 years before enabling genuinely novel capabilities.
For more analysis on AI and synthetic biology, connect with us today.